
The idea behind writing this article is to share my learning journey with other folks and to stay motivated to keep on exploring more. Even though I love writing, I usually end up dropping a lot of topics only because they are not exciting enough or there already is plenty of content out there. I want to try this format now where I just write my heart out without thinking about excitement or uniqueness of the topic.
So, LLMs. Need to introduction. What’s needed is a playground, a use case, and well, the motivation (or pressure) of keeping yourself up-to-date with the million new things that come out every month.
Playground- VS Code, Jupyter Notebook, Python, OpenAI or Azure OpenAI.
Use case- Document Question and Answering. In enterprise scenarios, querying on confidential/private data could bring a lot of value but it comes with the concern of data privacy. With options like Azure OpenAI or privategpt, it is possible. I’ll stick to Azure OpenAI in this article.
I’ve used Langchain as the framework to orchestrate LLM steps.
Where do we start? Embeddings.
Embeddings
Please note that embeddings is a highly mathematical and complex topic. Whatever you are going to read next is coming from a super dumb mind that tries to dumb things down so that this dumb guy could understand complex things. OpenAI’s doc is pretty good to start with- Embeddings.
I’ve been given a task to describe 5 of my friends. I don’t know where to start. So I just put them in 5 categories, or dimensions, and describe each of them based on those dimensions. Something like this-
| Name | Gender | Height (cm) | Weight (kg) | Hobby | Profession |
| Adam | Male | 190 | 90 | Working out | Warehouse supervisor |
| Sam | Male | 173 | 75 | Hiking | Banker |
| Julie | Female | 175 | 60 | Nail art | Social media influencer |
| Monica | Female | 157 | 55 | Baking | Security officer |
| Wei | Male | 179 | 79 | Hiking | Athlete |
Then, I’m asked which friend of mine I resemble with the most. In order to find similarity, I first need to put myself in those 5 categories.
| Name | Gender | Height (cm) | Weight (kg) | Hobby | Profession |
| Rohan | Male | 176 | 72 | Hiking | Sleep expert |
Now, I’ll start comparing each of my category/dimension with the same dimension of each of my friends. I’m not as tall and fit as Adam. Gender rules out Julie and Monica. I’m left with Sam and Wei.
At the first glance, it seems I’m similar to both. But we need to find the most likely match. So we start with comparing dimensions.
Gender, Hobby and Profession are either exactly similar or not relevant at all.
For height and weight, we will get in the Aryabhata zone and find the right answer. If the difference is less, it means more similarity.
Sam and Rohan (height)- 176-173 = 3
Sam and Rohan (weight)- 75-72 = 3
Wei and Rohan (height)- 179 – 176 = 3
Wei and Rohan (weight)- 79 – 72 = 7
So even if the difference in heights is same for Wei and Sam, weight becomes the differentiating factor, and makes Rohan more similar to Sam than Wei.
This is what embeddings are. They are numerical representation of strings. Similarity of strings is determined by the difference of numerical representations between them. In our use case of querying a document, instead of my friends, it’ll be chunks of documents represented in multiple dimensions. And, instead of Rohan, it’ll be the query whose dimensions will be compared against the dimensions of document chunks.
Models in AI could be thought of as a mathematical equation. An equation takes in some inputs, and returns the output. Models do the same. Embeddings model would take a string as an input, and return embeddings as the output. LLM models take string as an input, and return string as an output. (Way too much simplification)
This is how we can generate embeddings using a model-
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')
embeddings = model.encode("This is a sample text")
embeddings.shape
all-MiniLM-L6-v2 defines the input in 384 ways (dimensions). Rest of the code could be found in a notebook on my GitHub. There is an input file, corresponding to which an output file is generated which contains embeddings of each document present in the input.
Vector Database
As you can imagine, storing and comparing 384 dimensions of a given string with another string is a heavy task. That’s where Vector databases come in. They optimize the storage and querying of embeddings.
In Azure eco-system, Azure Cognitive Search supports vector search. I tried it out and it is a bit costly for my mini scale use case, but definitely an option worth exploring for enterprise grade solutions.
I’ve used ChromaDB which is an open source vector database that I can use to store and query embeddings locally in the notebook. This is the place where LLM will look for while finding answers to the query. Most relevant document chunks will be returned to the LLM, and the model will then add human touch to the response.
LLM
As part of this exercise, I wanted to import any document and use it for querying. Nothing is simpler than just fetching contents from a webpage. Instead of this webpage, it could be a private file location like Storage Account, S3, SharePoint, etc. I’ll stick to a publicly available webpage about the Data Protection Bill for this demo. This way, you could ask questions on latest internet data (just trying to hide my laziness)
Langchain has something called as a Retriever, which basically retrieves similar data from the vector store and feeds it back to the LLM.
query = "What are the duties of data fiducaries in the Digital Personal Data Protection Bill?"
qa_chain = RetrievalQA.from_chain_type(llm,retriever=retriever)
qa_chain({"query": query})
{'query': 'What are the duties of data fiduciaries in the Digital Personal Data Protection Bill?',
'result': 'According to the Digital Personal Data Protection Bill, 2023, the duties of data fiduciaries include maintaining the accuracy of data, keeping data secure, and deleting data once its purpose has been met. They must also obtain consent from individuals for processing their personal data, except in certain legitimate uses such as voluntary sharing of data by the individual or processing by the State for permits, licenses, benefits, and services. Data fiduciaries are also obligated to take measures to prevent, minimize, and mitigate risks of harm arising from processing of personal data. In case of a data breach, they are required to report it to the Data Protection Board of India and each affected data principal in a prescribed manner.'}
Azure Cost Report Analysis
I was asked recently at work to extract cost analysis reports of our subscription and to highlight some of the points like monthly average, annual cost, expensive resources, etc. I thought of trying out LLM against the analysis report to see if it returns accurate results.
In Langchain, there is something called as Agents. Agents help execute steps in a certain sequence, making it possible to chain different bits of pieces together. I’m yet to understand agents fully or make the most of out them, but I guess it worked for this use case.
I downloaded the cost report, fed it to the agent, and started asking questions.
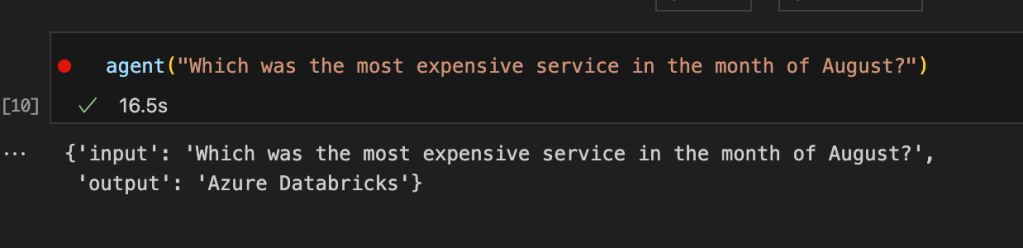
Here is the notebook which shows how it can be done. Pretty much straightforward as abstraction is our best friend. However, there are certain limitations I’ve bumped into that could not be ignored for production use cases. Trying to understand how can I make use of LLM for analysis in a better way, but this is good enough for a Saturday’s learning.
Conclusion
Enjoying the learning journey so far. The thing I’m struggling with is choosing between whether should I dive deeper into something or explore other tools which could potentially be better for my use cases. Running these things in production could definitely have more challenges. Storing vector in disk/memory could be a problem if the number of documents get high. Streamlining prompts, complex analysis use cases, and exploring Microsoft Semantic Kernel is something I’d mostly pick up next. Thanks for reading!

Leave a comment